# SpringCloudAlibaba
# 入门简介
# 为什么会出现SpringCloudAlibaba?
Spring CLoud Netflix 项目进入维护模式
# Nacos服务注册和配置中心
# 官网
https://nacos.io/en-us/
# 开始使用注册中心与配置中心
Nacos自带ribbon所以支持负载均衡,并采用默认轮询算法
启动后控制台页面
http://localhost:8848/nacos/#/login
注册中心直接看官方文档,很简单
https://spring-cloud-alibaba-group.github.io/github-pages/greenwich/spring-cloud-alibaba.html
中文文档:
https://nacos.io/zh-cn/docs/cluster-mode-quick-start.html
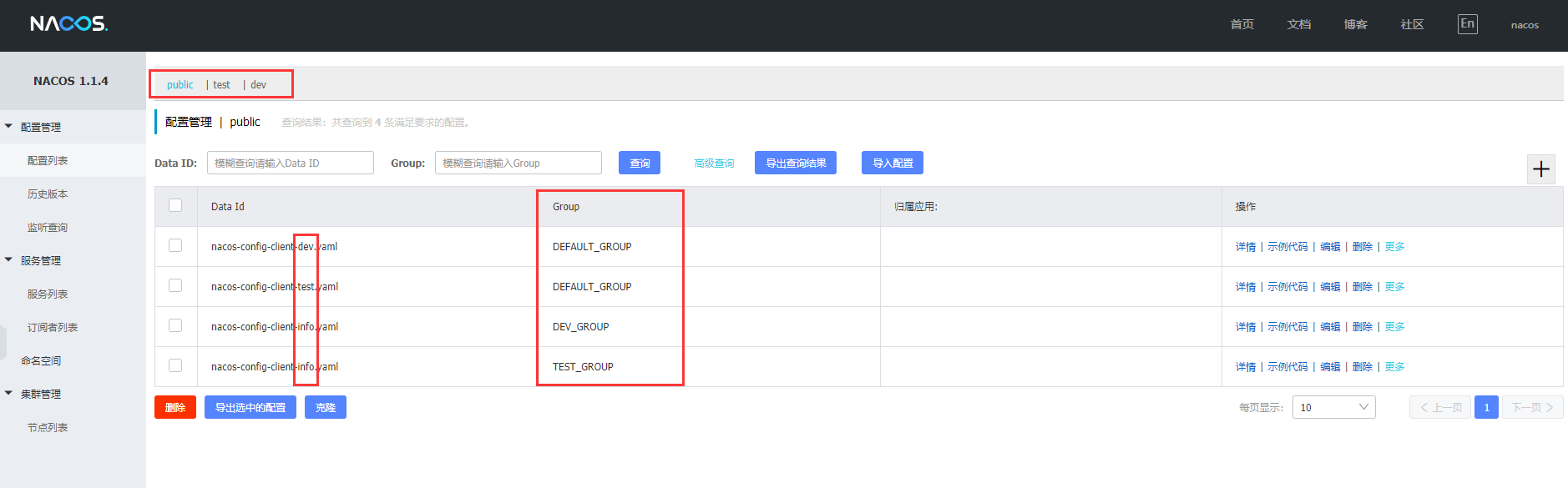
# 配置管理
Nacos有三层:
spring.cloud.nacos.config.namespace > spring.cloud.nacos.config.group > spring.profile.active
命名空间(例如华北机房与华南机房) > 分组(例如开发组与测试组) > 环境(例如开发环境,测试环境)
大概看这张图就差不多懂了
# 集群和持久化配置
# Nacos切换数据库(windows)
自带嵌入式数据库derby切换到mysql
执行安装目录的conf目录下的nacos-mysql.sql脚本初始化数据库环境
官网内容:
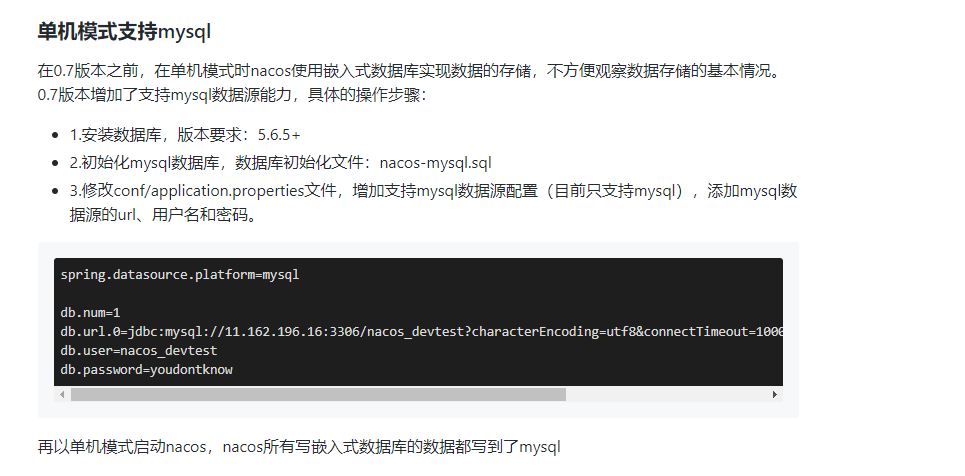
spring.datasource.platform=mysql
db.num=1
db.url.0=jdbc:mysql://11.162.196.16:3306/nacos_devtest?characterEncoding=utf8&connectTimeout=1000&socketTimeout=3000&autoReconnect=true
db.user=nacos_devtest
db.password=youdontknow
2
3
4
5
6
由于机器装的8.0.19mysql,单机版不支持不想下源码修改,然后就跳过
如果修改源码成功打包,配置的时候jdbc要加:serverTimezone=GMT%2B8 时区来适应mysql8
# Nacos集群
# 配置集群步骤
# 1.Linux服务器上mysql数据库配置
如上【Nacos切换数据库】
# 2.修改集群地址配置
# 先复制一份
cp cluster.conf.example cluster.conf
# 修改我们复制的
# 要在里面填写 hostname -i 查看的真实ip地址
cluster.conf
2
3
4
5
6
7
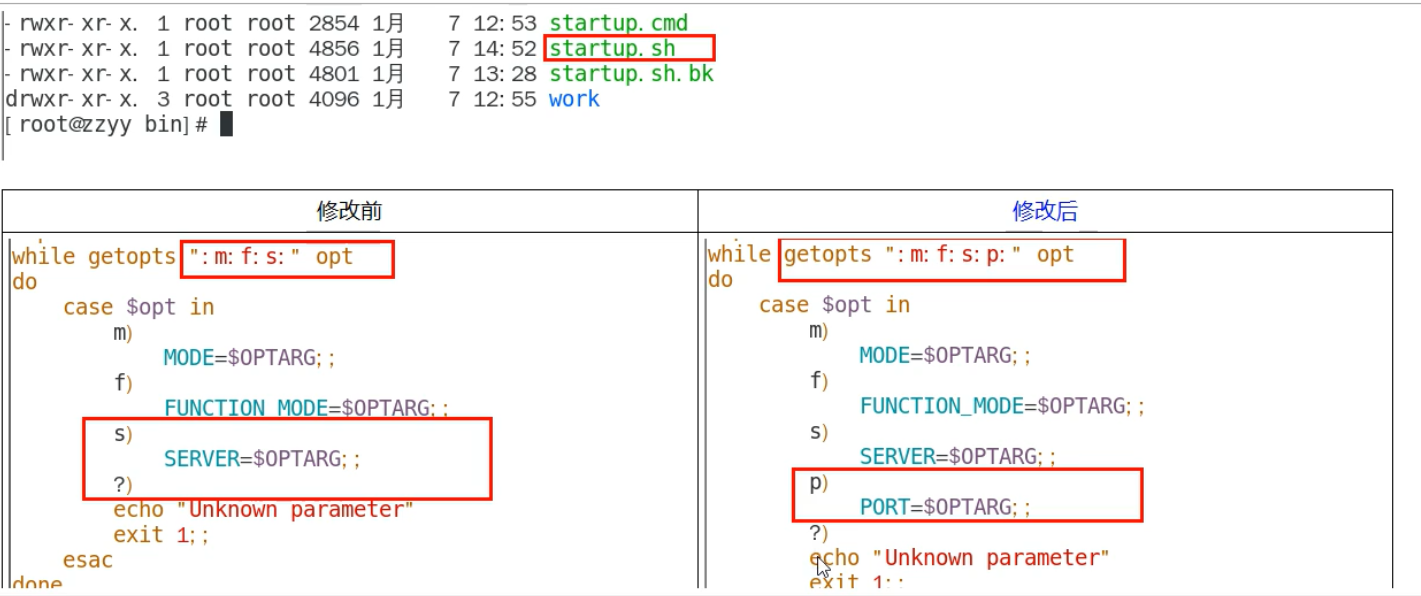
# 3.修改startup.sh

# 4.配置nginx.conf
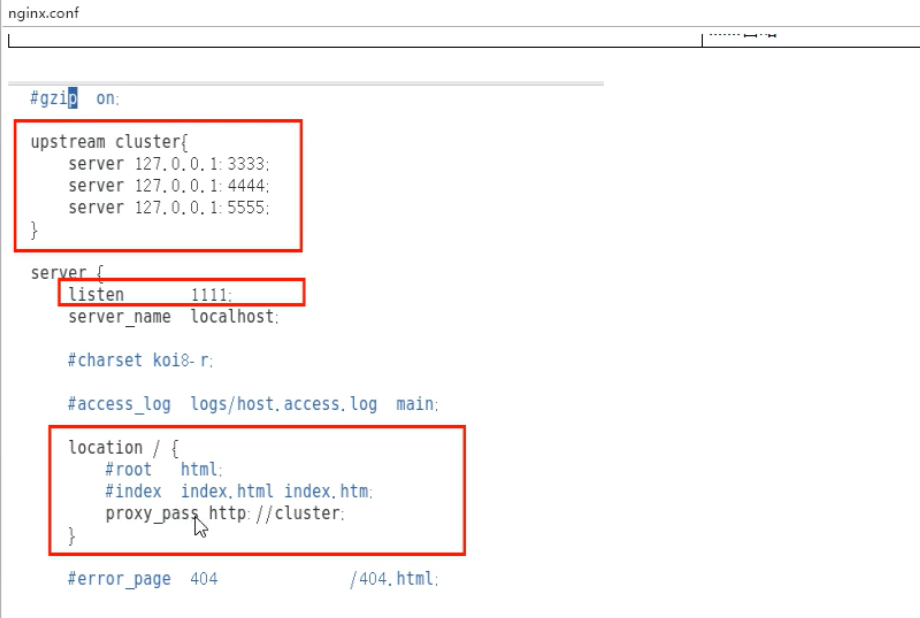
# 5.启动nginx
./nginx -c /apps/myNginx/conf/nginx.conf
# 6.访问nginx的http://192.168.172.22:1111/nacos/新建配置
可以看到数据库有数据表示搭建完成

# Sentinel 实现熔断与限流
# Sentinel启动
下载的是sentinel-dashboard-1.7.0.jar,java -jar启动即可
默认端口8080,账号密码sentinel
启动后就能访问控制台了,很方便

# 新建8401测试微服务
# 添加Sentinel依赖
<!-- sentinel -->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>
2
3
4
5
# 配置连接Sentinel
server:
port: 8401
spring:
application:
name: cloudalibaba-sentinel-service
cloud:
nacos:
discovery:
server-addr: 192.168.172.22:1111 # nacos注册中心
sentinel:
transport:
dashboard: 192.168.172.22:8080 #sentinel地址
# 默认8719端口,假如占用会自动从8719开始依次+1扫描,直至找到未被占用的端口
port: 8719
management:
endpoints:
web:
exposure:
include: '*'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 做一个controller,里面就两个简单的接口
package com.hzh.cloudalibaba.contoller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class FlowLimitController {
@GetMapping("/testA")
public String testA(){
return "-----testA";
}
@GetMapping("/testB")
public String testB(){
return "-----testB";
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
# 启动访问
Sentinel是懒加载的模式,需要访问一次接口才能有监控信息
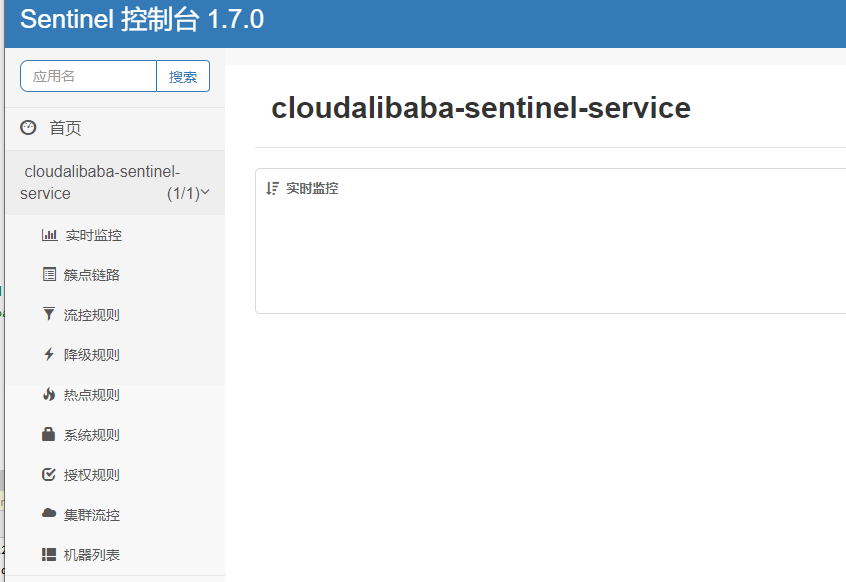
# 流控模式
# testA 每秒只允许请求一次
# 流控模式规则说明
- 资源名:唯一名称,默认请求路径
- 针对来源:Sentinel可以针对调用者进行限流,填写微服务名,默认default(不区分来源)
- 阈值类型/单机阈值:
- QPS(每秒钟的请求数量):当调用该api的QPS达到阈值的时候,进行限流
- 线程数:当调用该api的线程数达到阈值的时候,进行限流
- 是否集群:不需要集群
- 流控模式:
- 直接:api达到限流条件时,直接限流
- 关联:当关联的资源达到阈值时,就限流自己
- 链路:只记录指定链路上的流量(指定资源从入口资源进来的流量,如果达到阈值,就进行限流)【api级别的针对来源】
- 流控效果:
- 快速失败:直接失败,抛异常
- Warm Up:即预热/冷启动方式。在预热时长内先根据阈值/codeFactor(冷加载因子,默认3)的值流控,经过预热时长,才达到设置的QPS阈值
- 排队等待:匀速排队,让请求以均匀的速度通过,阈值类型必须设置成QPS,否则无效。
# 熔断降级
- 官网说明: https://github.com/alibaba/Sentinel/wiki/%E7%86%94%E6%96%AD%E9%99%8D%E7%BA%A7
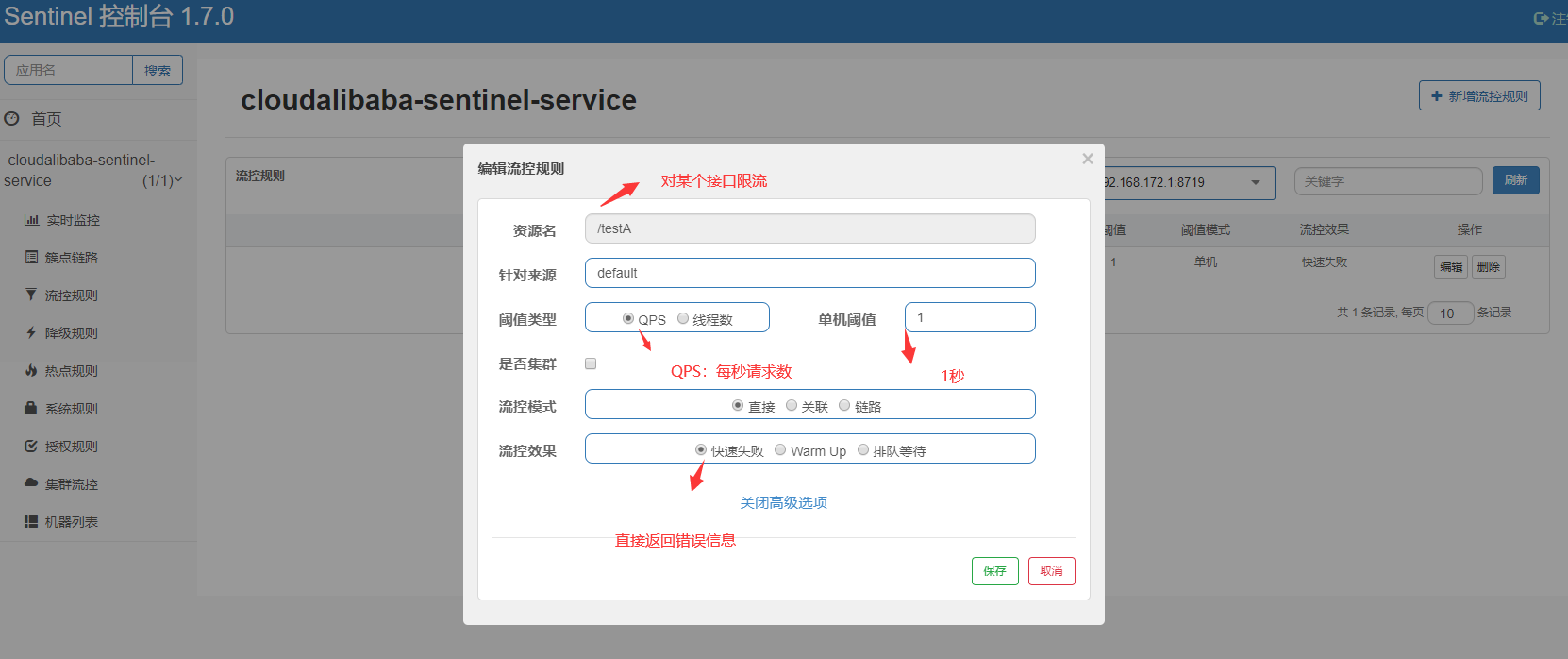
# 降级策略
- RT(平均响应时间)
当 1s 内持续进入 5 个请求,对应时刻的平均响应时间(秒级)均超过阈值(count,以 ms 为单位),那么在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地熔断(抛出 DegradeException)。注意 Sentinel 默认统计的 RT 上限是 4900 ms,超出此阈值的都会算作 4900 ms,若需要变更此上限可以通过启动配置项 -Dcsp.sentinel.statistic.max.rt=xxx 来配置。
- 异常比例
当资源的每秒请求量 >= 5,并且每秒异常总数占通过量的比值超过阈值(DegradeRule 中的 count)之后,资源进入降级状态,即在接下的时间窗口(DegradeRule 中的 timeWindow,以 s 为单位)之内,对这个方法的调用都会自动地返回。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。
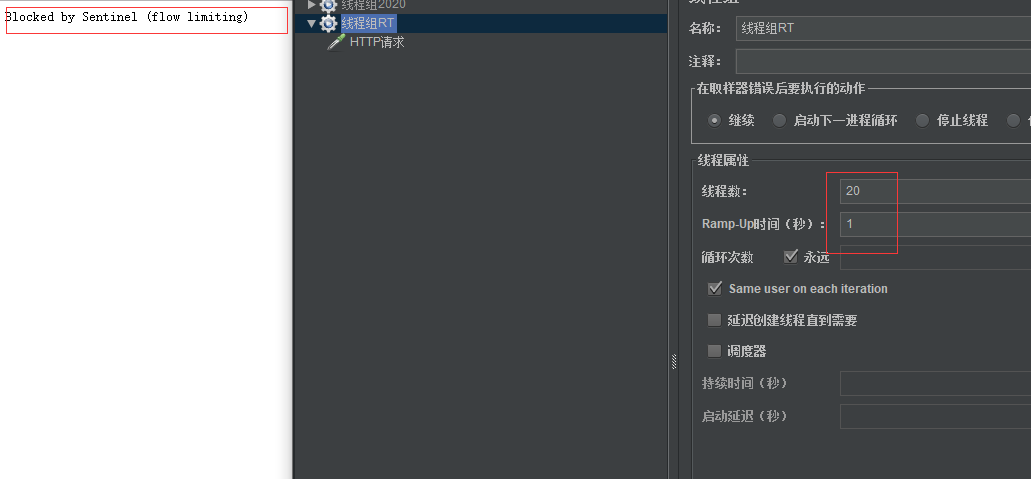
每秒进20个线程,阈值设置0.8,时间窗口设置1,请求方法写的是10/0。 结果请求量>5,异常比例100%,跳闸
- 异常数
当资源近 1 分钟的异常数目超过阈值之后会进行熔断。注意由于统计时间窗口是分钟级别的,若 timeWindow 小于 60s,则结束熔断状态后仍可能再进入熔断状态。
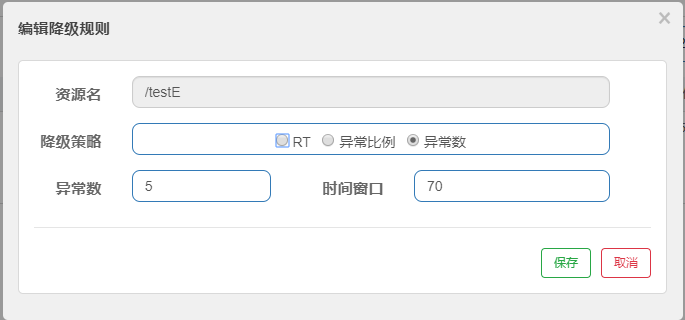
上图意思是,当异常数达到5个时,触发降级,在70s后回复。
# 热点规则
- 官网说明: https://github.com/alibaba/Sentinel/wiki/%E7%83%AD%E7%82%B9%E5%8F%82%E6%95%B0%E9%99%90%E6%B5%81
# Overview
何为热点?热点即经常访问的数据。很多时候我们希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行限制。比如:
- 商品 ID 为参数,统计一段时间内最常购买的商品 ID 并进行限制
- 用户 ID 为参数,针对一段时间内频繁访问的用户 ID 进行限制
热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流。热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效。
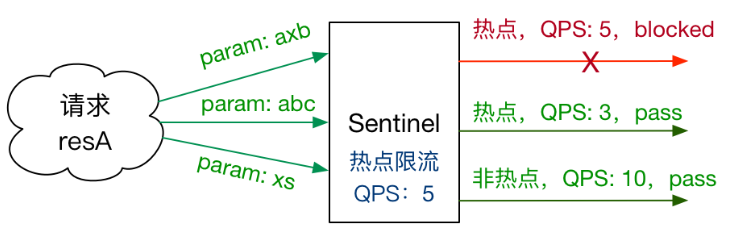
Sentinel 利用 LRU 策略统计最近最常访问的热点参数,结合令牌桶算法来进行参数级别的流控。热点参数限流支持集群模式。
根据官网所描述的,用自己的方式再描述一下
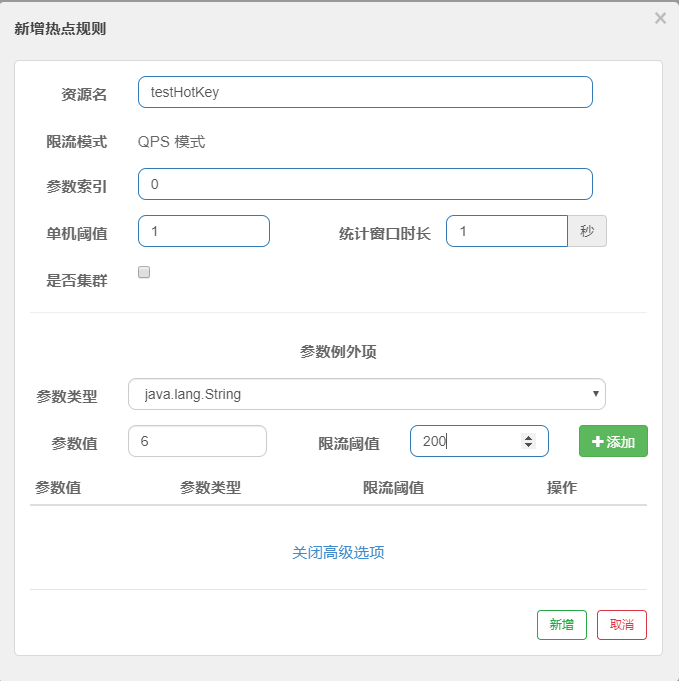
- 资源名:@SentinelResource的value
- QPS模式:每秒超过阈值则降级
- 参数索引:在接口的下标为0(就是第一个)参数
- 单机阈值:1秒内若带着索引为0(第一个)参数请求次数大于1,拉闸
- 统计窗口时长:1秒内恢复正常
参数额外项
- 参数类型:controller参数接收类型
- 参考值:当索引0的参数为6时,指定一个限流阈值
- 限流阈值:当索引0的参数为6时,指定一个限流阈值
@GetMapping("/testHotKey")
@SentinelResource(value = "testHotKey",blockHandler = "deal_testHotKey")
public String testHotKey(@RequestParam(value = "p1",required = false) String p1,
@RequestParam(value = "p2",required = false) String p2){
return "----testHotKey";
}
public String deal_testHotKey(String p1, String p2, BlockException exception){
return "-----deal_testHotKey,/(ㄒoㄒ)/~~";
}
2
3
4
5
6
7
8
9
10
# 系统自适应限流
- 官网说明 https://github.com/alibaba/Sentinel/wiki/%E7%B3%BB%E7%BB%9F%E8%87%AA%E9%80%82%E5%BA%94%E9%99%90%E6%B5%81
Sentinel 系统自适应限流从整体维度对应用入口流量进行控制,结合应用的 Load、CPU 使用率、总体平均 RT、入口 QPS 和并发线程数等几个维度的监控指标,通过自适应的流控策略,让系统的入口流量和系统的负载达到一个平衡,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
# 背景
在开始之前,我们先了解一下系统保护的目的:
- 保证系统不被拖垮
- 在系统稳定的前提下,保持系统的吞吐量
长期以来,系统保护的思路是根据硬指标,即系统的负载 (load1) 来做系统过载保护。当系统负载高于某个阈值,就禁止或者减少流量的进入;当 load 开始好转,则恢复流量的进入。这个思路给我们带来了不可避免的两个问题:
- load 是一个“结果”,如果根据 load 的情况来调节流量的通过率,那么就始终有延迟性。也就意味着通过率的任何调整,都会过一段时间才能看到效果。当前通过率是使 load 恶化的一个动作,那么也至少要过 1 秒之后才能观测到;同理,如果当前通过率调整是让 load 好转的一个动作,也需要 1 秒之后才能继续调整,这样就浪费了系统的处理能力。所以我们看到的曲线,总是会有抖动。
- 恢复慢。想象一下这样的一个场景(真实),出现了这样一个问题,下游应用不可靠,导致应用 RT 很高,从而 load 到了一个很高的点。过了一段时间之后下游应用恢复了,应用 RT 也相应减少。这个时候,其实应该大幅度增大流量的通过率;但是由于这个时候 load 仍然很高,通过率的恢复仍然不高。
TCP BBR 的思想给了我们一个很大的启发。我们应该根据系统能够处理的请求,和允许进来的请求,来做平衡,而不是根据一个间接的指标(系统 load)来做限流。最终我们追求的目标是 在系统不被拖垮的情况下,提高系统的吞吐率,而不是 load 一定要到低于某个阈值。如果我们还是按照固有的思维,超过特定的 load 就禁止流量进入,系统 load 恢复就放开流量,这样做的结果是无论我们怎么调参数,调比例,都是按照果来调节因,都无法取得良好的效果。
Sentinel 在系统自适应保护的做法是,用 load1 作为启动自适应保护的因子,而允许通过的流量由处理请求的能力,即请求的响应时间以及当前系统正在处理的请求速率来决定。
# 系统规则
系统保护规则是从应用级别的入口流量进行控制,从单台机器的 load、CPU 使用率、平均 RT、入口 QPS 和并发线程数等几个维度监控应用指标,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性。
系统保护规则是应用整体维度的,而不是资源维度的,并且仅对入口流量生效。入口流量指的是进入应用的流量(EntryType.IN),比如 Web 服务或 Dubbo 服务端接收的请求,都属于入口流量。
系统规则支持以下的模式:
- Load 自适应(仅对 Linux/Unix-like 机器生效):系统的 load1 作为启发指标,进行自适应系统保护。当系统 load1 超过设定的启发值,且系统当前的并发线程数超过估算的系统容量时才会触发系统保护(BBR 阶段)。系统容量由系统的 maxQps * minRt 估算得出。设定参考值一般是 CPU cores * 2.5。
- CPU usage(1.5.0+ 版本):当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0),比较灵敏。
- 平均 RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒。
- 并发线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护。
- 入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护。
# @SentinelResource 自定义限流处理逻辑
定义全局限流异常处理类,注意方法必须为static
package com.hzh.cloudalibaba.myhandler;
import com.alibaba.csp.sentinel.slots.block.BlockException;
import com.hzh.springcloud.entities.CommonResult;
/**
* 自定义限流处理逻辑
*/
public class CustomerBlockHandler {
public static CommonResult handlerException(BlockException exception){
return new CommonResult(444,exception.getClass().getCanonicalName() + "\t" + "服务不可用");
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Controller类@SentinelResource注解演示
@GetMapping("/byResource")
@SentinelResource(value = "byResource",blockHandlerClass = CustomerBlockHandler.class,blockHandler = "handlerException")
public CommonResult byResource(){
return new CommonResult(200,"按资源名称限流测试OK",new Payment(2020L,"serial001"));
}
2
3
4
5
- 如果资源名填的是【/byResource】则依然会走默认的处理方法
- blockHandler 管控制台流控异常
- fallback 管java/业务/运行时异常
# 规则持久化
- 加pom
<!-- sentinel持久化 -->
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>
2
3
4
5
- yml 添加nacos数据源配置
# 配置nacos数据源
spring:
application:
name: nacos-order-consumer
cloud:
nacos:
discovery:
server-addr: 192.168.172.22:1111 # 配置Nacos地址
sentinel:
transport:
dashboard: 192.168.172.22:8080 #sentinel地址
# 默认8719端口,假如占用会自动从8719开始依次+1扫描,直至找到未被占用的端口
port: 8719
# 配置nacos数据源
datasource:
ds1:
nacos:
server-addr: 192.168.172.22:1111
dataId: cloudalibaba-sentinel-service
groupId: DEFAULT_GROUP
data-type: json
rule-type: flow
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
- 登录nacos新建配置,选json
- resource:资源名称
- limitApp:来源应用
- grade:阈值类型,0表示线程数,1表示QPS
- count:单机阈值
- strategy:流控模式,0表示直接,1表示关联,2表示链路
- controlBehavior:流控效果,0表示快速失败,1表示Warm up,2表示排队等待
- clusterMode:是否集群
[
{
"resource": "/rateLimit/byUrl",
"limitApp":"default",
"grade":1,
"count":1,
"strategy":0,
"controlBehavior":0,
"clusterMode":false
}
]
2
3
4
5
6
7
8
9
10
11
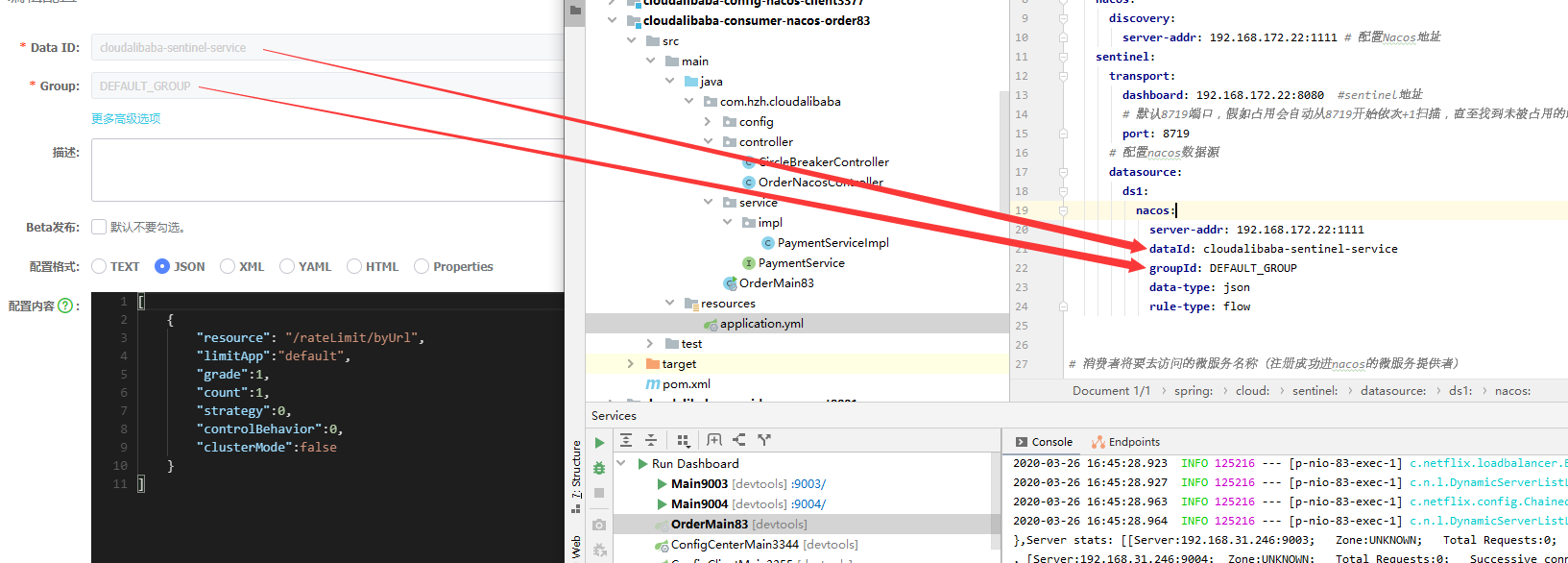
接着发现能持久化了。 其实也就是sentinel的配置放到nacos里去
# Seata处理分布式事务
# 官网
https://seata.io/zh-cn/
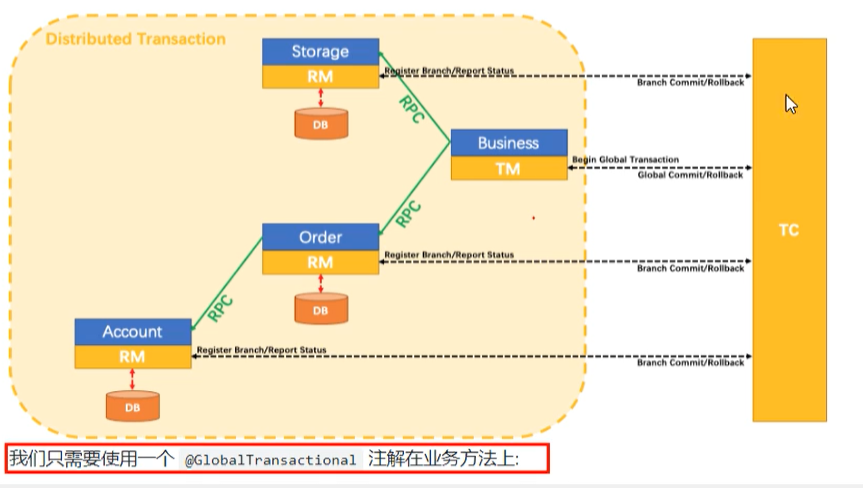
# 术语
- Transaction ID XID (非官网,分布式事务处理过程的-ID+三组件)
全局唯一的事务ID
- TC - 事务协调者
维护全局和分支事务的状态,驱动全局事务提交或回滚。
- TM - 事务管理器
定义全局事务的范围:开始全局事务、提交或回滚全局事务。
- RM - 资源管理器
管理分支事务处理的资源,与TC交谈以注册分支事务和报告分支事务的状态,并驱动分支事务提交或回滚。
图解:
# 开始使用
# 1.设置数据源 - file.conf
主要修改:自定义事务组名称+事务日志存储模式为db+数据库连接信息
- 自定义事务组名称 - service模块
service {
#vgroup->rgroup
vgroup_mapping.my_test_tx_group = "fsp_tx_group"
#only support single node
default.grouplist = "127.0.0.1:8091"
#degrade current not support
enableDegrade = false
#disable
disable = false
#unit ms,s,m,h,d represents milliseconds, seconds, minutes, hours, days, default permanent
max.commit.retry.timeout = "-1"
max.rollback.retry.timeout = "-1"
}
2
3
4
5
6
7
8
9
10
11
12
13
14
- 事务日志存储模式为db - store模块
## transaction log store
store {
## store mode: file、db
mode = "db" # file 换成db并指定数据库
## file store
file {
dir = "sessionStore"
# branch session size , if exceeded first try compress lockkey, still exceeded throws exceptions
max-branch-session-size = 16384
# globe session size , if exceeded throws exceptions
max-global-session-size = 512
# file buffer size , if exceeded allocate new buffer
file-write-buffer-cache-size = 16384
# when recover batch read size
session.reload.read_size = 100
# async, sync
flush-disk-mode = async
}
## database store
db {
## the implement of javax.sql.DataSource, such as DruidDataSource(druid)/BasicDataSource(dbcp) etc.
datasource = "dbcp"
## mysql/oracle/h2/oceanbase etc.
db-type = "mysql"
driver-class-name = "com.mysql.jdbc.Driver"
url = "jdbc:mysql://127.0.0.1:3306/seata"
user = "mysql"
password = "mysql"
min-conn = 1
max-conn = 3
global.table = "global_table"
branch.table = "branch_table"
lock-table = "lock_table"
query-limit = 100
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
- 初始化db
找到seata/conf/db_store.sql 初始化
# 2.设置注册中心 - registry.conf
file 改成nacos,并设置nacos地址
registry {
# file 、nacos 、eureka、redis、zk、consul、etcd3、sofa
type = "file"
nacos {
serverAddr = "localhost"
namespace = ""
cluster = "default"
}
2
3
4
5
6
7
8
# 3.准备3个数据库

从上到下依次是
- 账户信息库
- 订单库
- 库存库
从上到下依次创建了相应的表
seata_account库
CREATE TABLE t_account(
'id' BIGINT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY COMMENT 'id',
'user_id' BIGINT(11) DEFAULT NULL COMMENT '用户id',
'total' DECIMAL(10,0) DEFAULT NULL COMMENT '总额度',
'used' DECIMAL(10,0) DEFAULT NULL COMMENT '已用余额',
'residue' DECIMAL(10,0) DEFAULT '0' COMMENT '剩余可用额度'
) ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
INSERT INTO seata_account.t_account('id','user_id','total','used','residue') VALUES('1','1','1000','0','1000')
2
3
4
5
6
7
8
9
seata_order库
CREATE TABLE t_order(
`id` BIGINT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
`user_id` BIGINT(11) DEFAULT NULL COMMENT '用户id',
`product_id` BIGINT(11) DEFAULT NULL COMMENT '产品id',
`count` INT(11) DEFAULT NULL COMMENT '数量',
`money` DECIMAL(11,0) DEFAULT NULL COMMENT '金额',
`status` INT(1) DEFAULT NULL COMMENT '订单状态:0:创建中; 1:已完结'
) ENGINE=INNODB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
2
3
4
5
6
7
8
seata_storage库
CREATE TABLE t_storage(
'id' BIGINT(11) NOT NULL AUTO_INCREMENT PRIMARY KEY,
'product_id' BIGINT(11) DEFAULT NULL COMMENT '产品id',
'total' INT(11) DEFAULT NULL COMMENT '总库存',
'used' INT(11) DEFAULT NULL COMMENT '已用库存',
'residue' INT(11) DEFAULT NULL COMMENT '剩余库存'
) ENGINE=INNODB AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;
INSERT INTO seata_storage.t_storage('id','product_id','total','used','residue')
VALUES('1','1','100','0','100');
2
3
4
5
6
7
8
9
10
订单-库存-账户3个库下都需要建各自的回滚日志表
\seata-server-0.9.0\seata\conf目录下的db_undo_log.sql
最终效果
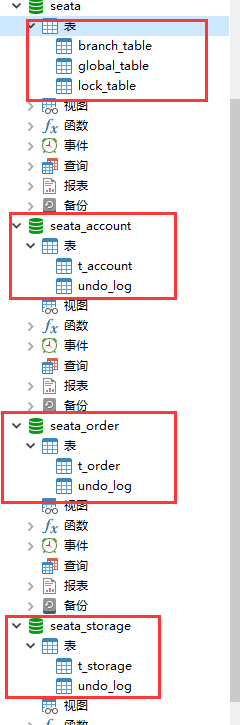
# 订单-库存-账户三个微服务
在主业务方法上加上下面注解就能做到分布式事务控制
@GlobalTransactional(name = "fsp_tx_group",rollbackFor = Exception.class)
@GlobalTransactional里当然还有很多属性,有时间深入研究
# 分布式事务的执行流程
- TM开启分布式事务(TM向TC注册全局事务记录)
- 换业务场景,编排数据库,服务等事务内资源(RM向TC汇报资源准备状态)
- TM结束分布式事务,事务一阶段结束(TM通知TC提交/回滚分布式事务)
- TC汇总事务信息,决定分布式事务是提交还是回滚
- TC通知所有RM提交/回滚资源,事务二阶段结束。
贴一张 TC - TM - RM 的理解图
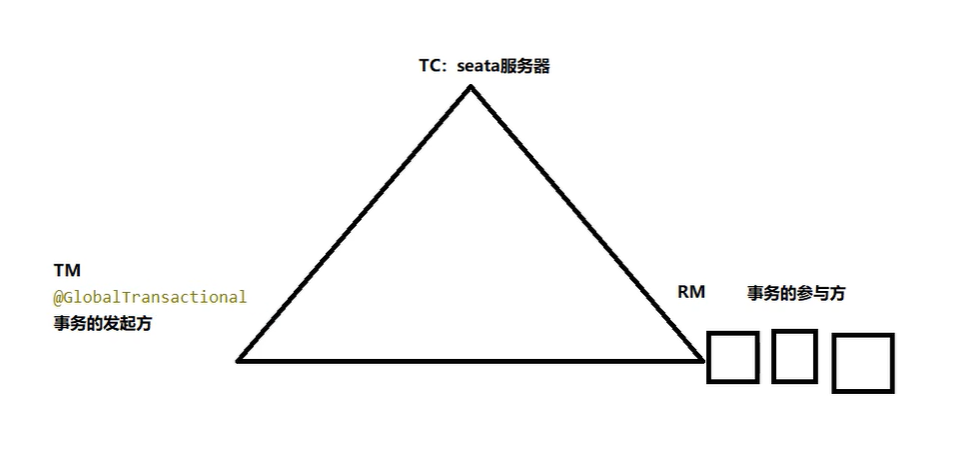
# Seata 原理简介
# 一阶段加载
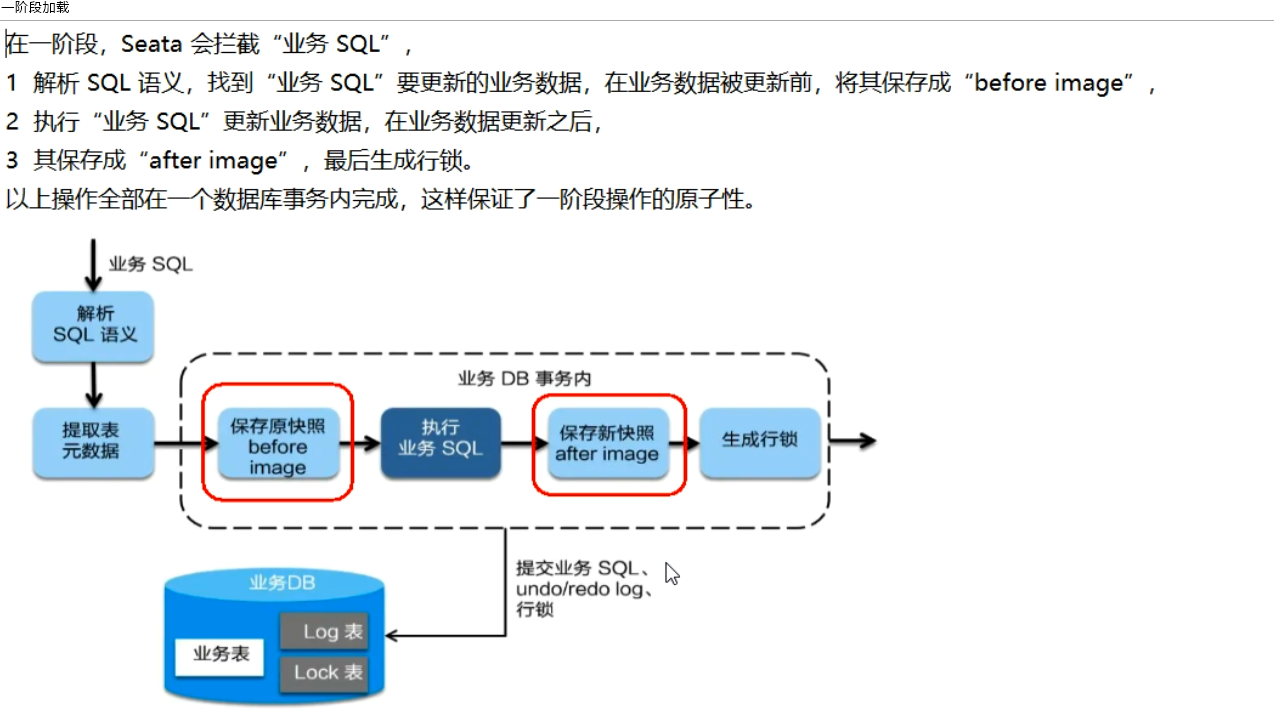
# 二阶段提交(正常情况)
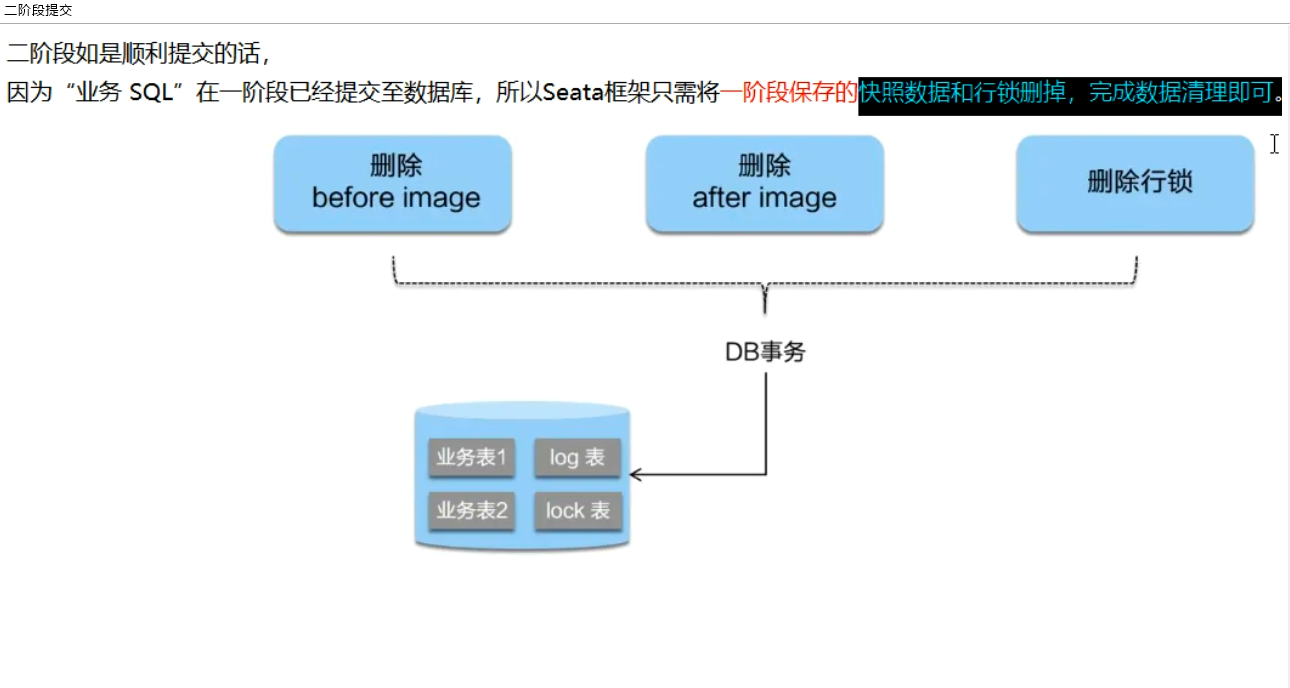
# 二阶段回滚(异常情况)